UDBS + DAIS + VIS
Modelování a analýza
Datový model - množina konceptů, které mohou být použity pro popis struktury databáze; 3 hlavní kategorie
- Konceptuální - model nezávislý na použité technologii databází
- Databázový - závislý na technologii, ale ne konkrétním jazyce (pro relační databáze -> Relační datový model)
- Fyzický - závislý na jazyce, reprezentuje fyzické uložení dat na médiích (cache vs pevné disky, halda atp viz jiná kap)
Konceptuální model
Určujeme následující pojmy
- Entita - objekt reálného světa - prakticky záznam v tabulce
- Atribut - vlastnost entity - prakticky sloupec v tabulce
- Entitní typ - množina entit se stejnými atributy - prakticky datová tabulka
- Klíč - jeden či více atributů, které jednoznačně určují entitu v množině entit
- Integritní omezení - podmínka, která musí být splněna, aby entita byla validní
- Mezi entitními typy se zaznamenává vztah (relace)
- Kardinalita vztahu - dělení vztahů na 1:1, 1:M, M:M
- Povinnost vztahu
Graficky konceptuální model znázorňujeme užitím ER Diagramu (entity relationship diagram)
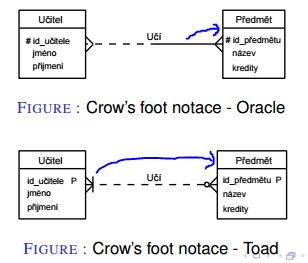
Modrá šipka znázorňuje povinnost vazby a k jaké tabulce se vztahuje. Znázorněný diagram v obou případech popisuje, že učitel musí mít předmět.
Poslední možná reprezentace je užitím UML diagramů, konkrétně třídního diagramu přímo se mapujícího na databázi (přiznak persistent)
Analýza
Datová analýza
- výstupem je konceptuální model
- analyzujeme data, která budou v databázi, jejich vlastnosti, zpravidla zapisujeme do tabulky do tzv. Datového slovníku

- konkrétní konceptuální model pak tvoříme vztažený na konkrétní datový slovník
Funkční analýza
- řeší funkce systému
- vypisujeme všechny funkce systému, řešíme jejich vstupy a výstupy, kdo k ní může přistupovat.
- Netriviální funkce popisujeme podrobněji, popřípadě píšeme i pseudokód.
Dalšími analýzami může být stavová analýza (entity mohou nabývat nějakých stavů - dokončeno, vytvořeno, probíhá...), analýza požadavků (respektive specifikace), analýza grafického rozhraní
Relační datový model
Databázový model specifický pro relační databáze
Relace = tabulka, jejíž řádky jsou záznamy, její sloupce jsou atributy, některé z atributů mohou být cizí klíče, tedy odkazovat na atributy jiné relace/tabulky
Na relacích máme 3 základní dotazovací operace vycházející z relační algebry neměnící samotný model
- selekce - vybrání určitých řádků(WHERE,IN, LIKE)
- projekce - vybrání určítých sloupců (SELECT * / SELECT jméno)
- spojení - (JOIN)
Další operace na změnu relačního modelu (aktualizace) - CREATE, INSERT, DELETE, UPDATE...
Funkční závislost + dekompozice
Funkční závislost - vztah mezi atributy X->Y, takový, že X bude vždy ovlivňovat Y. Například název->typ, sprite -> pití, není možné aby dva záznamy obsahující sprite, měli odlišný typ. Naopak to tvrdit nemůžeme. Další příklady může být číslo objednávky -> zákazník, položky; rodné číslo -> datum narození)
Pomocí funkčních závislostí se předchází problémům jako je rendundance (zbytečné opakování záznamů) nebo nekonzistence.
- Datová analýza
- Udělání jedné supertabulky kde všechny atributy patří do jedné tabulky
- Zjištění fuknčních závislostí
- Rozdělení tabulky na menší, tak, aby byla odstraněna redundance (užitím funkčních závislostí) a zároveň aby všechny funkční závislosti zůstaly zachovány.
Armstrongovy axiomy
Funkčních závislostí i v rámci jedné tabulky může být velmi mnoho. Tyto axiomy popisují odvozování těchto závislostí bez nutnosti je všechny zapisovat.
Operace na axiomech je podobná operacím na relacích/zobrazení -> Sjednocení, Dekompozice, Tranzitivita.
Normálové formy
Kandidátní klíč - minimální(pokud ji zmenšíme, nebude unikátní) unikátní množina atributů =>nikde se neopakuje => jednoznačně ukazuje na konkrétní řádek
- 1NF - obsahuje pouze atomické hodnoty = žádná buňka neobsahuje více hodnot; žádné duplicitní řádky
- 2NF - 1NF + v případě složeného kandidátního klíče, musí levá strana závislosti tvořit celý klíč
- 3NF - 2NF + všechny závislosti jsou tvořeny na levé straně pouze primárními klíči.
- BCNF - 3NF + žádní kandidáti na klíč (kombinace atributů, které jednoznačně definují řádek)nesdílejí atribut
Existuje i 4NF a 5NF
Dotazovací jazyky
Relační algebra
Pracujeme s relacemi(množinami); kromě samozřejmých operací (sjednocení, průnik, rozdíl a kartézský součin) máme definované i operace selekce, projekce a spojení.
SQL
Standard, více revizí pojmenovaných dle roku jako SQL-86, SQL:2011...
Standard ne vždy při implementaci konkrétního jazyka (MSSQL, MySql, Oracle SQL,...) byly k dispozici všechny konstrukce, tvůrci jazyka si je vytvářeli sami. Jazyky nejsou zcela kompatibilní.
Některé SQL Servery nabízejí i procedurální rozšíření (Oracle: PL/SQL, Microsoft: T-SQL), ty jsou však diametrálně odlišné.
SQL je deklarativní jazyk = příkazy popisují co chceme, ale ne JAK
JMD/DML vs JDD/DDL
JMD - jazyk manipulace dat (Data manipulation language) = SELECT, UPDATE, DELETE, INSERT
JDD - jazyk definice dat (Data definition language) = CREATE, ALTER, DROP
Transakce, zotavení, log, ACID, Commit a Rollback
- Operace, která se běžně užívá pro seskupení mnoha operací, mezi nimiž je databáze v nevalidním/nekonzistentním stavu. Užití transakcí snižuje počet přístupů k databázi.
- Každá transakce musí splňovat učité vlastnosti - ACID
- A - Atomicity - Proběhnou všechny operace v transakci, nebo žádná
- C - Consistency - přechod z jednoho konzistentního stavu do druhého (nemůže se stát porušení integritního omezení)
- I - Isolation -Každá transakce je nezávislá na jiných transakcích
- D - Durability - Proběhlé operace jsou trvalé a přetrvávají i v případu výpadku systému
- Commit - provede veškeré operace a zapíše je do databáze.
- Rollback - operace používaná v případě chyby. Zruší veškeré změny provedené v transakci.
- Zotavení probíhá po systémové chybě, aby se databáze vrátila zpět do korektního stavu.
- Systémové chyby řadíme do více kategorií
- Výpadek proudu
- Selhání systému
- Selhání DBMS (SŘBD)
- Techniky zotavení
- Odložená aktualizace - zápis do DB až po COMMITu - NO-UNDO/REDO
- Okamžítá aktualizace - zápis ihned do DB - NO-REDO/UNDO
- Kombinovaná aktualizace - kombinace obojího
PL-SQL + T-SQL
- PL-SQL pro Oracle, T-SQL pro Microsoft (a Sybase)
- Rozšíření umožňující efektivnější práci s jednotlivými záznamy
- Umožňují zachytávání výjimek
- Zavedení práce s kurzory a proměnnými
- Optimalizace výkonu procedur, spouštění přímo na serveru, nezávislé na jazyku samotné aplikace
- Funkce provádějící ihned nějakou operaci po předem specifikované DML operaci

- Mohou být anonymní, či pojmenované
- Provádí určitou operaci, nemají návratovou hodnotu
- Může přijímat deklarovaný počet parametrů. Některé z těchto parametrů mohou být určeny k výstupu.

- Oproti procedurám mají specifikovaný návratový typ a vždy vrací hodnotu

- Kurzory jsou pomocne proměnné vytvořené po provedení nejakého SQL příkazu. Slouží k procházení tohoto příkazu
- Dva typy
- Implicitní kurzor - automaticky vytvořený po DML příkazu (INS,DEL,UPD)
- Explicitní kurzor - deklarovaný v definiční části procedury.
Fyzický návrh databáze; tabulka typu halda, index (B-strom a hashování), shlukování záznamů
- Implicitní volba při CREATE TABLE
- Záznamy jsou vkládany na 1. volnou pozici nebo na konec -> rychlý insert O(1)
- Záznamy nejsou implicitně seřazeny -> O(n) SELECT
- Záznamy nejsou implicitně mazány pouze flagovány -> SHRINK command
- Záznamy jsou při tvoření ihned řazeny dle primárního klíče -> neefektivní insert
- Jelikož jsou záznamy již seřazeny mohou se záznamy vybírat například binárním vyhledáváním
- Klíče jsou uchovávány ve speciálních strukturách
- B+ strom - balancovaný strom, pointer vždy na další prvek, O log(n)
- Složený index - index na více polích, při vyhledávání pouze jednoho z atributů je složitost stejná, jako by klíč neexistoval (vhodné na konkrétní kombinace)
- Hashovací tabulka - klíče nejsou uspořádany, ale vyhledávání jednoho záznamu je značně rychlé
- Bitmapový index - vhodný ná klíče, které nabývají pouze malých hodnot (pohlaví, rodinný stav, booleany, atp.)
- Záznamy nejsou implicitně mazány pouze flagovány -> SHRINK command
Vykonávání dotazů, Plán dotazu, ladění
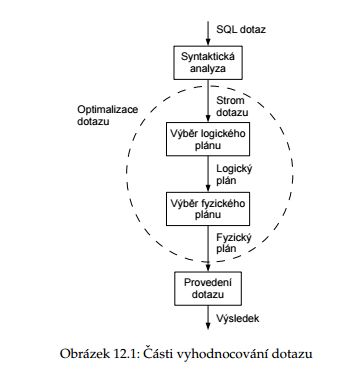
- SQL dotazy nejsou v databázi vykonávany přesně tak, jak jsou deklarovány.
- Existuje optimalizátor, které příkazy modifikuje do podoby s menší cenou
- Optimalizace probíhá na základě relační algebry.
- Počet alternativních plánů roste exponenciálně, pouze několik plánů je ohodnoceno -> výsledná cena nemusí být nutně nejnižší možná.
- Optimalizace má 4 hlavní kroky
- Syntaktická analýza - Převod dotazu do relační algebry (vygenerování stromu)
- Vybrání logického plánu - vybrání nejlepšího stromu (relační algebra)
- Vybrání fyzického plánu - vybrání konkrétních algoritmů (SQL) subčásti dotazu
- Provedení dotazu - Sestavení plánů = pospojování fyzických plánů dle vybraného logického plánu
- Dvě zásadní části každé optimalizace
- Dochází k minimalizaci plánu a k vynechání redundantních částí
- Přeuspořádání jednotlivých operací, aby výsledek zabral co nejméně času a zdrojů
Objektově-relační datový model
- Díky nákladné migraci relačních dat, vznikl objektově-relační datový model
- Zavedení kolekcí, dědičnosti, referencí/dereferencí, ukazatelů
- Objektové typy a jejich funkce jsou uloženy spolu s daty v databázi (netřeba je tak pro každou aplikace vytvářet znovu)
- Datové typy můžeme pak používat v nových RELAČNÍCH i OBJEKTOVÝCH tabulkách.

Datová vrstva informačního systému
- Datová vrstva informačního systému odděluje aplikaci od databáze. Jde o třídy a funkce zajišťující komunikaci s databázi.
- Návrhové vzory na této vrstvě
- Data Access Object / Data Mapper
- Active Record (není zrovna typickým zástupcem vhodným pro třívrstvou arch.
- Row Data Gateway - instance = jeden řádek tabulky; obsahuje vyhledávací třídu, která nám vytváří instance. Může implementovat Table Data Gateway
- Table Data Gateway - instance = tabulka; možno implementovat ve vyhledávací třída RDGateway
- API k databází = rozhraní umožňující přistupovat do databáze. Například vykonávat QUERY z programovacího prostředí.
- ODBC = Open database Conectivity = nezávislá na programovacím jazyce, obsahuje ovladače prakticky ke všem relačním databázím, ale i například k CSV
- JAVA -> JDBC
- .NET -> ADO.NET
- Díky nákladné migraci relačních dat, vznikl objektově-relační datový model
- Zavedení kolekcí, dědičnosti, referencí/dereferencí, ukazatelů
- Objektové typy a jejich funkce jsou uloženy spolu s daty v databázi (netřeba je tak pro každou aplikace vytvářet znovu)
- Datové typy můžeme pak používat v nových RELAČNÍCH i OBJEKTOVÝCH tabulkách.
Souběh, řešení souběhu, úrovně izolace
- Souběh = více přístupů k stejným datům v tentýž moment
- Mohou nastat následující stavy
- Read + Read => no problem no worries
- Read + Write => Nekonzistentní analýza = Probíhá sekvence čtení, již přečtené záznamy se ovšem mohou vlivem jiné transakce změnit a výsledkem je nekonzistence.
- Write + Read => Nepotvrzená závislost = druhá transakce čte po zápise, který však ještě nebyl COMMITnut a byl později ROLLBACKnut.
- Write + Write => Ztráta aktualizace = první transakce úspěšně zapíše, druhá ji však přepíše
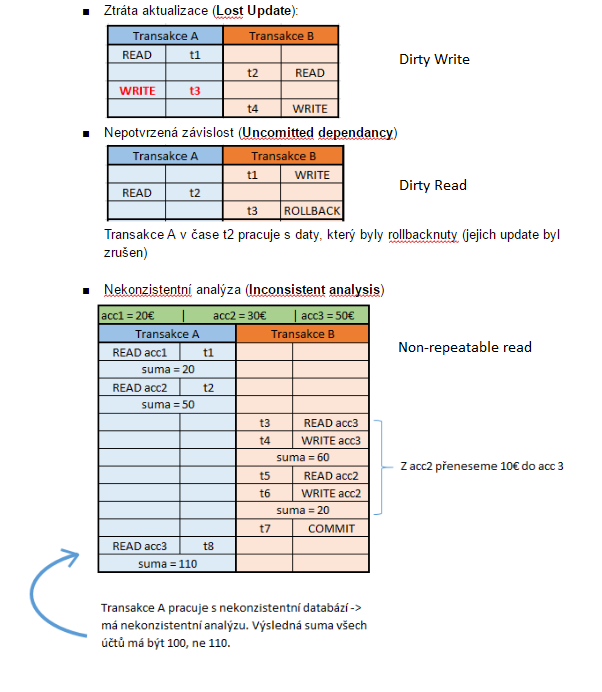
Řešení souběhu
- Pesmistické = zámkování = předpokládáme, že souběh nastává
- Existující dva druhy zámků
- S = read lock = transakce držící tento zámek, může ze záznamu číst, ale ne zapisovat
- X = write lock = transakce držící tento zámek, může ze záznamu číst a zapisovat do něj.
- zámek S může získat více transakcí zároveň. Pokud existuje zámek X, může jej vlastnit pouze jedna transakce a nesmí existovat S.
- V případě, že transakce chce zapisovat a má S (a žádný jiný zámek S na záznamech není), S se upgraduje na X.
- V případě, že např dvě transakce drží S a obě chtějí psát (požádají na X), budou čekat nekonečný čas navzájem =>deadlock.
- Deadlock lze řešit - timeoutem, detekce grafem, modifikace zámků s timestamps (Wait-die / Wound-wait)
- Optimistické řešení = verzování
Úrovně izolace
- Read uncommited - transakce může číst i mezistavy jiné transakce
- Read commited - vidí stavy pouze před začátkem dotazu, zámky mohou být uvolněny před ukončením transakce
- Repeatable read - stavy se nemohou změnit v průběhu transakce, ale mohou mezitím přibýt nové
- Serializable - maximální úroveň izolace = pokud tam je zámek nelze přidávat, měnit, mazat...
Architektura a struktura informačního systému......
Architektura
- Jedná se o velice abstraktní pojem náhledu na celý systém
- zahrnuje základní strukturu/organizaci onoho systému
- tzn. propojení komponent, jejich fyzické rozmístění, jeho principy, vztahy s okolím...
- každá strana - vývojář, zákazník, investor,... pochopí, co se odehrává
Návrh
- Vychází z architektury, jedná se o konkretizaci problémů a jejich řešení
- ergo JAK a s ČÍM systém pracuje
Nasazení
- popisuje KDE systém běží (na jakém HW, platformě,…).
Struktura IS
- Komponenta - oddělená část systému s rozhraním
- Konektor - kanál mezi komponentami, konkrétně mezi jejich rozhraními
- Konfigurace - konkrétní propojení komponent pomocí konektorů
Tři kompetence informačního systému a třívrstvá architektura. Logická a fyzická architektura informačního systému. Vzory pro enterprise architekturu. Zajištění doménové logiky, přístupu k datům, objektově-relačního chování. Principy objektově-relačního mapování a mapování dědičnosti
3 Kompetence + 3vrstvá architektura
- Odpovídají třívrstvé architektuře
- Komunikace s uživatelem (prezentační vrstva)
- Zpracování informací a dočasné uchování (business vrstva)
- Trvalé uchování dat (databázová vrstva)
Logická a fyzická architektura informačního systému.
- Logická = rozdělení např. na třívrstvou architekturu. To je standard více méně. Občas i včetně servisní vrstvy.
- Fyzická = konkrétní rozmístění komponent v reálném světě (rozmístění na serverech atp.)
P of EAA
- Vzory pro doménovou logiku
- Transaction script - každý dotaz z pretentační vrstvy (do business vrstvy) má vlastní funkci.
- Domain model - rozdělení business vrstvy do "sítě propojených objektů".
- Table module - jedna instance spravuje jednu tabulku v databázi (všechny její řádky)
- Service layer - obaluje celou strukturu/business logiku a jasně definuje co s aplikací lze dělat.
- Vzory pro datovou vrstvu (ORM)
- Table data gateway
- Row data gateway
- Active record
- Data mapper (DTO+DAO)
- Objektově-relační chování
- Unit of work
- Lazy load
- Identity map - objekt v paměti žije jen jednou. Pokud pro objekt sahame poprve - vytvoří se (new), pokud ho bude chtit i někdo jiny, tak mu posle tento a nebude vytvaret novy z DB.
- Objektově-relační struktury
- Identity field - mapování primary key do integeru v dané instanci.
- Foreign Key Mapping - namapování cizího klíče jako reference na objekt.
- Assocation Table Mapping - Pokud máme M:N, potrebujeme asociační tabulku v DB.
- Dependent mapping - jedna classa dokáže mapovat jak celek tak jeho dílčí části (Album<kompozice>->Track --> AlbumMapper, není třeba TrackMapper)
- Embedded value - mapování vlastního datového typu do tabulky jiného objektu.
- Serialized LOB - BLOB (Graf) do DB...Asi k ukládání obrovské struktury za účelem zálohy? Když nemá smysl vytvářet nový Relační model...
- Mapování dědičnosti
- Single table inheritance - jedna tabulka na všechny třídy. nevýhoda je NULL hodnot v DB.
- Class table inheritance - pro každou třídu existuje tabulka, ale nejsou nezávislé. Jsou v nich nadefinované pouze věci, co přidávají hodnotu. Nevýhoda je pro vytvoření jednoho objektu zápis do x tabulek.
- Concrete table inheritance - pro každou třídu exisutje konkrétní tabulka. Nevýhoda je redundance dat.
Životní cyklus informačního systému, Zachmanův framework. Úlohy, role, otázky. Principy týmového vývoje informačního systému. Principy a fáze Unified Process. Robustní a agilní přístupy při vývoji informačního systému.
Životní cyklus informačního systému.
- Vize
- Analýza
- Návrh
- Implementace
- Nasazení
- Provoz
Zachmanův framework. Úlohy, role, otázky.
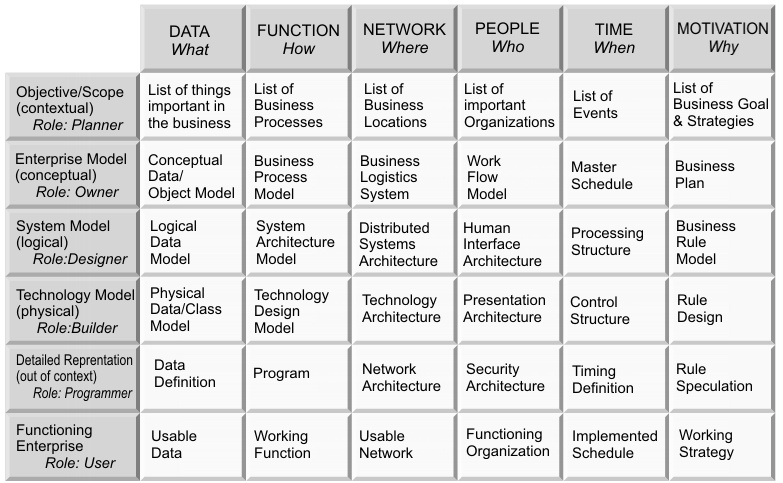
- CO? Jde zejména o informace samotné.
- JAK? Jde o procesy prováděné s informacemi.
- KDE? Na jakých místech se pracuje s informacemi.
- KDO? Kdo a v jaké roli pracuje s informacemi.
- KDY? Kdy a na základě jakých impulzů se s informacemi pracuje
- PROČ? Jde o cíle a pravidla, jak těchto cílů dosáhnout.
Popis rolí, artefaktů a procesů probíhajících při vývoji IS, rozdělených do vrstev podle základních otázek (co, kdo, kde, kdy, jak, proč) a úrovní granularity (high-level abstraktní pohled, low-level detailní implementační pohled)
© Kuba Beránek